MapReduce使用cleanup()方法实现排序筛选后输出 |
您所在的位置:网站首页 › clean up的用法 › MapReduce使用cleanup()方法实现排序筛选后输出 |
MapReduce使用cleanup()方法实现排序筛选后输出
|
背景
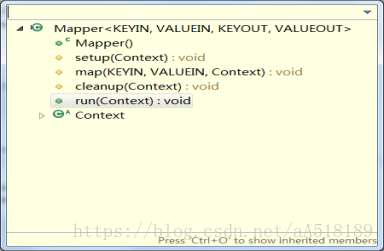
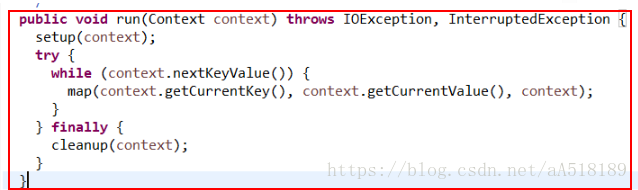
MapReduce的map和reduce方法有一个局限性,就是map()方法每次只处理一行,而reduce()方法每次只处理一组。并且reduce一般都是将处理每一组数据后的结果都写出。但有时候想要只输出一部分结果,比如在Wordcount程序中,想要输出单词数量前三的统计信息,这时就可以用cleanup()方法来实现。 cleanup()简介在hadoop的源码中,基类Mapper类和Reducer类中都是只包含四个方法:setup方法,cleanup方法,run方法,map方法。如下所示: 其方法的调用方式是在run方法中,如下所示: 可以看出,在run方法中调用了上面的三个方法:setup方法,map方法,cleanup方法。 对于每个maptask和reducetask来说,都是先调用run()方法,因此根据源代码中run()方法的结构可以看出,不管是map任务还是reduce任务,程序都要经过如下几个阶段:调用run()方法-->调用setup(context)方法-->循环执行map()或reduce()方法-->最后调用cleanup(context)方法 其中setup方法和cleanup方法默认是不做任何操作,且它们只被执行一次。但是setup方法一般会在map函数之前执行一些准备工作,如作业的一些配置信息等;cleanup方法则是在map方法运行完之后最后执行 的,该方法是完成一些结尾清理的工作,如:资源释放等。如果需要做一些配置和清理的工作,需要在Mapper/Reducer的子类中进行重写来实现相应的功能。map方法会在对应的子类中重新实现,就是我们自定义的map方法。该方法在一个while循环里面,表明该方法是执行很多次的。run方法就是每个maptask调用的方法。 hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。 setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高! cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高! 所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行。 实例cleanup()除了可以做一些资源释放工作,还能实现一些高级功能。比如对结果进行筛选后输出。下面是一个具体的例子。 功能需求:将单词出现次数前三的单词按照次数降序输出单词及对应的次数 实现思路:由reduce任务的执行顺序可知,在reduce()方法全部执行完后会执行cleanup()方法。而在通常的Wordcount程序中,reduce()方法只是将相同单词的值累加,然后就以价值对的形式输出了。并没有重写cleanup()方法做进一步的操作。因此,可以考虑通过reduce()将每个词的次数累加后先不输出,而是将键值对存入到一个map集合中。将所有组的数据计算完成并添加到map中后,此时map中的数据是无序的。下面调用cleanup()方法,重写cleanup()方法,让它对map集合做排序和筛选工作,最后将结果写出。 代码: import java.io.IOException; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.LinkedList; import java.util.List; import java.util.Map; import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class CleanUp_test { public static class WsMapper extends Mapper { @Override public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException { String[] split = value.toString().split(" "); for (String word : split) { context.write(new Text(word), new IntWritable(1)); } } } public static class WsReducer extends Reducer{ Map map=new HashMap(); public void reduce(Text key, Iterable iter,Context conext) throws IOException, InterruptedException { int count=0; for (IntWritable wordCount : iter) { count+=wordCount.get(); } String name=key.toString(); map.put(name, count); } @Override public void cleanup(Context context)throws IOException, InterruptedException { //这里将map.entrySet()转换成list List list=new LinkedList(map.entrySet()); //通过比较器来实现排序 Collections.sort(list,new Comparator() { //降序排序 @Override public int compare(Entry arg0,Entry arg1) { return (int) (arg1.getValue() - arg0.getValue()); } }); for(int i=0;i |
【本文地址】
今日新闻 |
推荐新闻 |